The promise and pitfalls of private data
As we each move through the physical world, and interact in the digital world, our activities leave digital traces. When these traces are combined with the traces of others, they form valuable data sources that can be used to advance scientific understanding and improve our lives. But these digital traces also contain sensitive personal information whose misuse could cause significant harm. Government regulations can sometimes limit the ability of institutions to collect and use information about us, but they often lag far behind current data usage practices. Technological approaches to privacy, developed by computer scientists and statisticians, are an increasingly important means for ensuring data is adequately protected.
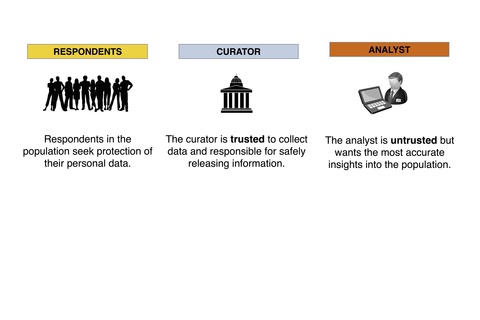
Associate Professor Gerome Miklau's research into data privacy enables large-scale data analysis that is safe for individuals. One of his main goals is to develop methods for extracting useful aggregate facts about a group without disclosing sensitive information about the individuals in the group. For example, his research could enable doctors to use a collection of medical records to investigate the correlation between obesity and diabetes, without revealing the particular medical details of any single individual. It could allow urban planners to study a database of employees' commuting patterns without revealing the exact home or work location of any individual. And his techniques could be used by sociologists to study the structure of a social network, for example, to understand how rumors spread in a community, without revealing any particular friendship relation between individuals. "Ultimately, this area of privacy research reveals the extent to which personal privacy is compatible with hoped-for benefits of data analysis," says Miklau.
Much of Miklau's recent privacy research has focused on the model of differential privacy, which provides a formal standard for protecting individuals' personal information. When a differentially-private algorithm is used to study a dataset, individuals who contribute to the dataset receive the compelling assurance that the information released will be virtually indistinguishable whether or not their personal data is included. To achieve this standard of protection, the results of computations on the dataset cannot be released unmodified: they must be transformed by random perturbation. "This causes information loss, diminishing the utility of the results, compared to what would have been possible in the absence of privacy concerns," adds Miklau. "A major goal of research in this area is to satisfy differential privacy while reducing information loss as much as possible."
As his research has shown, sophisticated algorithms can often result in greater accuracy with no sacrifice of privacy. However, to achieve these improvements, it is typically necessary to consider each data analysis task carefully, customizing the algorithm to the task. Miklau's research group has produced state-of-the-art algorithms for performing basic statistical analysis on tabular data (in which each record describes the properties of an individual). His group also developed some of the earliest differentially-private algorithms for networked data (which describes individuals along with their relationships or interactions with one another). An ongoing goal of his research is to generalize these techniques, making it easier to discover new privacy algorithms and apply them to new tasks.
Miklau recently began exploring a new and quite different approach to managing sensitive personal information. Personal data often has great value to the institutions that wish to analyze it, and it has a potential cost to the individuals who contribute data due to privacy risks. "Perhaps a price can be placed on personal data, allowing it to be bought and sold in a marketplace," says Miklau. "While most privacy methods insist on imposing strict limits on the disclosure of information, a market-based approach instead allows personal information to be exposed, as long as individuals are properly compensated."
This approach is motivated by the fact that data is increasingly treated as a commodity. Markets for (mostly business-related) data are growing quickly on the Web, driven by large corporations like Microsoft and Amazon, as well as start-ups that are collecting and selling data. Large data brokers also collect and sell data about individuals for marketing purposes. However individuals are rarely compensated, even when their personal information is widely disseminated.
Miklau, along with collaborators at the University of Washington, is investigating how an open market for personal information could be designed. In such a market, an analyst would submit questions about a population of individuals to a broker, but would be required to pay for answers. In fact, random perturbation can be added to the answers and the analyst could be asked to pay more for answers that are more accurate. Once payment is received, the data broker is responsible for fairly distributing the income received to contributing individuals. The major challenges include determining how the price should depend on the accuracy of released data and avoiding attacks by market participants who may attempt to avoid paying the given price by carrying out arbitrage in the market.
Miklau received his Ph.D. in Computer Science from the University of Washington in 2005. He earned Bachelor's degrees in Mathematics and in Rhetoric from the University of California, Berkeley, in 1995. He was awarded the ACM PODS Alberto O. Mendelzon Test-of-Time Award in 2012, a UMass Amherst Lilly Teaching Fellowship in 2011, an NSF CAREER Award in 2007, and the ACM SIGMOD Dissertation Award in 2006.